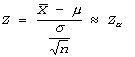ALPHABETICAL GLOSSARY OF USEFUL STATISTICAL AND
RESEARCH RELATED TERMS
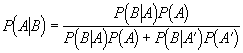
where P (A|B) is the probability of event A given that event B has occurred, P (A) is the probability of event A, and P (A’) is the probability of event A not occurring. Bayes theorem can be used to overcome some of the interpretive and philosophical shortcomings of frequentist or classical statistical methods.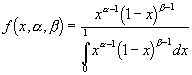
where a and b are shape parameters, the mean is a / (a + b), and variance is ab / [(a + b +1)(a + b)]![]()
where x is the number of “successes” out of n trials, p is the probability of success, and ! represents the factorial operator, such that 3! = 3 x 2 x 1.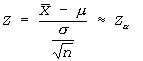
The distribution of random variable Z approaches that of the standard normal distribution as n approaches infinity.![]()
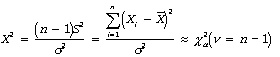
![]()
where, X2 is the computed test statistic, I is the number of classes or intervals in a frequency histogram, fi is the observed frequency in histogram class I=i, fi (0) is the expected frequency in histogram class I=i under the hypothesized distribution, and c2a is the critical value of the chi-square distribution with (I-1) degrees of freedom and level of significance alpha.![]()
where P (A Ç B) is the probability that both event A and B occur.![]()
where bhat are estimated parameters, b are true population parameters, n is sample size, and e is a positive small difference between estimated and true population parameters.![]()
![]()
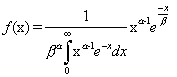
where alpha and beta are shape parameters. The mean and variance of the gamma distribution are m = ab and s2 = ab2 respectively.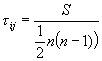
where S is the sum of scores (see non-parametric statistic reference for computing scores) and n is sample size.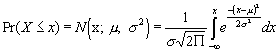
![]()
where sij is the covariance between variables i and j, and si and sj are the standard deviations of variables i and j respectively.![]()
where, x is the number of occurrences per interval, l is the mean number of occurrences per interval, a is the mean rate of occurrence (occurrence per unit time, length, or space), DT is the interval length, and l = a DT.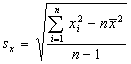
where n is the sample size and xave is the sample mean. The sample standard deviation shown here is a biased estimator, even though the sample variance is unbiased, and the bias becomes larger as the sample size gets smaller. ![]()
The new variable Z is normally distributed with m=0 and s=1, and is a standard normal variable.![]()
where P(A Ç B) is the probability that both event A and B occur.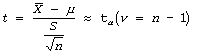
where n is the sample size.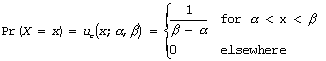
where, x is the value of random variable X, a is the lower most value of the interval for x, and b is the upper most value of the interval for x.